Under Review
RoboGaze: Evaluating Robot World Models via Structured Vision-Language Analysis
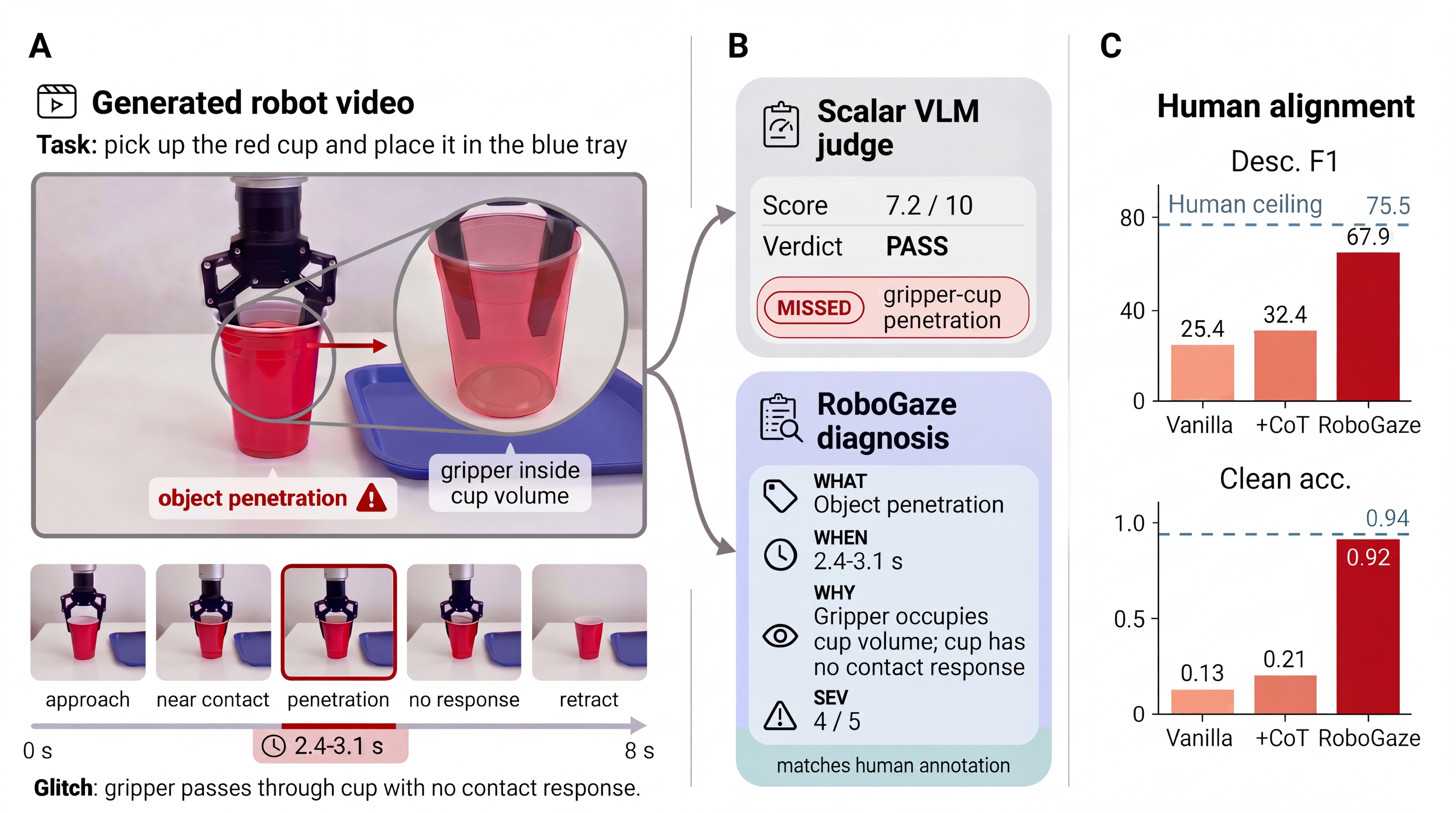
A training-free, multi-agent VLM evaluator that turns generated robot-manipulation videos into structured, temporally localized diagnostic reports — telling you what failed, when, why, and how severely.
Minh-Loi Nguyen1,
Nghiem Tuong Diep2,
Hung Khang Nguyen2,
Minh Le2,
Doanh Le Thien1,2,
Hoang H. Tran1,
Dung Duy Le1,
Vu Duong1,
Daniel Sonntag3,
An Thai Le1,2,6,
Duy M. H. Nguyen3,4,5,
Ngo Anh Vien†1,2,
Tran Van Nhiem†2
1Center for AI Research, VinUniversity 2VinRobotics 3DFKI 4University of Stuttgart 5Max Planck Research School for Intelligent Systems 6Technische Universität Darmstadt
†Project Leads